
MBAで網羅するデータサイエンス関連の科目について、ご紹介したいと思います。
数あるMBAプログラムにおいて、各校がどの程度データサイエンスに力を入れているのかは、学校によって様々です。今回は、MBAプログラムが取り扱うことの多い、データサイエンス関連の科目について触れてみたいと思います。
そもそも、MBAスクールでなぜデータサイエンスを教えるのか?という疑問については、【MBA】なぜビジネスリーダーにデータサイエンスが必要とされるのか?
にてご紹介しておりますので、併せてご覧ください。
MBAプログラムがデータサイエンス科目として教える5つのこと
①数字を読むのに必要な、統計学の基礎知識
 データ分析を行うのに、数字を正しく理解できていなければ話になりませんので、統計学の基礎的な知識を授業で網羅します。
データ分析を行うのに、数字を正しく理解できていなければ話になりませんので、統計学の基礎的な知識を授業で網羅します。
「そんな、数字くらい読めるよ~!」という声が返ってきそうですが、意外にも物事を間違って捉えてしまう数字の読み方をする方は多いです。
私が好きで引用する例に、「日本人の”平均”年収」があります。
国税庁の発表している、民間給与実態統計調査結果(令和元年)によれば、1年を通じて勤務した給与所得者の1人あたりの”平均”給与は、約436万円だったそうです。
これを聞いて、「大体そんなものだよね。」と思いましたか?
それとも、「え、意外に高いんだな…」と思いましたか?
いずれにせよ、約436万円という数字を聞いて、以下のようなグラフを思い浮かべた方は、注意が必要です。
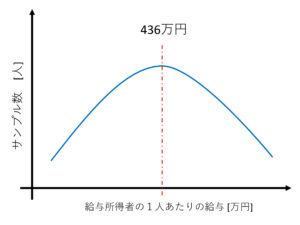
このグラフは、給与の平均は約436万円で、なおかつ給与を436万円くらい貰っている人の割合が最も多い、ということを示すグラフです。
しかし、実態は異なります。
厚生労働省の発表した賃金構造基本統計調査から計算すると、1年を通じて勤務した給与所得者の1人あたりの給与の”中央値”は、約370万円になります。
つまり、給与分布の正しいグラフは下のようになります。
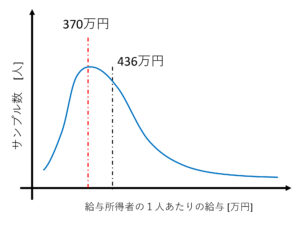
最も多く存在するのは、年収436万円の人ではなく、年収370万円の人だということです。
平均値というのは、極端な値(この例で言えば、年収を数千万円貰っている人のデータ)に影響を受けやすいため、平均値が中央値よりも大きくなってしまいます。
平均年収が約436万円と聞いて、「なるほど、じゃあ450万円前後の給与を貰っているのが最も多いんだな。」と解釈したあなたは、数字を読み違えている可能性がある、ということです。
数字が読めるようになるため(分析結果が何を意味するのか、分かるようになるため)に、MBAでは以下のような分野を勉強します。
興味のある方は、調べてみてください。
- データの種類、代表値
- 確率
- 分散と標準偏差
- サンプリング
- 信頼区間
- 仮説検定
- 相関関係と因果関係
- 回帰分析とp値
②構造化データの統計解析や機械学習(Excel、R、Python)

引用:https://iblnews.org/the-open-edx-platform-prepares-its-upgrade-into-python-3/
数字が読めるようになったら、データを分析してパターンを見出したり、未来を予測します。
それが、統計解析や機械学習になります。
ここで言う構造化データとは、ある定められた形に整形されたデータのことで、例えばExcelシートにまとめられた顧客データ表やPOSデータが当てはまります。
データの格納形式が決められているので、データ分析が容易なのが特徴です。
対する非構造化データとは、特定の目的に合わせて成形されていないデータのことで、メールやSNS上の投稿、写真や画像等がそれにあたります。
MBAでは、まず構造化データに対する統計解析や機械学習を行う演習をします。
(学校によっては、アドバンスドクラス等で非構造化データの解析にも触れるようです。)
以下に、構造化データに対する統計解析や機械学習の例を示しておきます。
- 回帰分析により、クーポンを使用した顧客はそうでない顧客と比較して、顧客単価がどう変化したかを調べる。
- 当日の天候や気温によって来場者数が上下するイベントについて、過去の降水確率、気温のばらつき、過去のイベント来場者数と収益のトレンドを示すデータからイベントの収益を予測する。
- 顧客情報(性別や年齢、年収、クーポンの受け取り有無等)と取引履歴(購入日、購入商品名、購入数等)から学習し、顧客の購買行動に応じて複数のグループに分ける(クラスタリング)。例えば、Aグループ:クーポンへの反応が良い節約家、Bグループ:値下げはあまり気にしない品質重視、等。学習結果を利用して新規顧客の所属するグループを予想し、店舗運営に活用する。
簡単な分析であれば、Excelを用いた統計解析も十分に可能です。
複雑な計算を要する分析は、プログラミング言語(RやPython)を使います。
近年のブームに影響を受けているのか、Pythonを統計解析用言語として教えるプログラムが多いようです。
③社内に蓄積されていくデータの管理(SQL)

引用:https://learntocodewith.me/posts/sql-guide/
データの活用方法が分かったら、今度はいかにデータを蓄積するか、またはいかにそれを引き出してくるかを学びます。
企業活動から収集できるデータを活用することが一番多いと思いますので、後で分析することも考えて、データの蓄積方法をデザインしていきます。
「とにかくデータを溜めておけば、後で何か役に立つだろう。」という考えは少し甘いです。
何も考えずに溜められたデータというのは、解析前にクレンジング(データ形式の統一や整理)が必要です。
実際のところ、データサイエンティストやアナリストは、このクレンジングの作業に約80%の時間を割いているとのデータもあるようです。
マネージャーとしては、「データをどう分析するか?」に加えて、「データをどう格納するか?」という戦略を練る必要があります。
データを溜める方法が決まったら、データを抽出する作業に移ります。
意外かもしれませんが、企業が蓄積するデータというのは、1枚のエクセルシートにすべてのデータがまとめて保管されているわけではなく、用途に合わせたいくつものエクセルシートに分割されて蓄積されています。
例えば、顧客情報管理シートには、顧客の名前やID、電話番号、住所や生年月日等が格納されており、取引情報シートには、顧客ID、取引日、取引商品名と数量、担当従業員名、従業員ID等が格納されています。
マネージャーが、「○○市に住む顧客の平均顧客単価を知りたい。」と思えば、顧客情報管理シートと取引情報シートの情報を「顧客ID」で紐づけし、顧客情報の住所で○○市のものを抽出し、平均顧客単価を割り出す、ということが必要です。
これができるようになるために、MBAではSQLというデータベース言語を学習します。
SQLという言語を使えば、上で説明したようなデータの抽出や、データベースの更新等ができます。
④意思決定につなげられるデータの可視化技術(Tableau, PowerBI)
データに意味づけができたら、それを意思決定者が分かるように上手く見せる必要があります。
例えば、「ここ20年の間、世界中でどの会社のゲームがどれだけ売れているんだ?」という疑問を持ったとすると、直近20年の企業別ゲーム売り上げを表にまとめても良いですが、以下のようなグラフを作って見せると、各社の盛衰がより直感的に理解できますね。

MBAでは、データ可視化に特化したツール(例えば、 TableauやMicrosoft PowerBI等)を使って意思決定者にデータを上手く見せるための演習を行います。
これらのツールを用いれば、新型コロナウイルスの蔓延状況に関する膨大な情報を、下のような1枚のダッシュボードにまとめることができます。
⑤ファイナンスやマーケティングに活用するモデリング
 ファイナンスやマーケティングといえば、MBAの核ともいえる代表的な科目ですが、これらに非常に密接した形でデータサイエンスを学ぶこともできます。
ファイナンスやマーケティングといえば、MBAの核ともいえる代表的な科目ですが、これらに非常に密接した形でデータサイエンスを学ぶこともできます。
例えばファイナンスで言えば、大量のファイナンスデータを取り込んで、将来の株価や収益率、景気動向を予測するモデルを構築することができます。
マーケティングで言えば、大量の顧客情報と取引履歴に関するデータを取り込んで、必要なマーケティングアクション(広告を打つ・販促メールを送る・値下げを行う、等)をどの顧客にいつ行えば収益が最大化されるのか、予測を行うことができます(ダイナミックモデリング)。
まとめ:MBAプログラムがデータサイエンス科目として教える5つのこと

いかがでしょうか。
MBAで学ぶデータサイエンスについて、イメージを膨らませることができていれば幸いです。
参考:



コメント